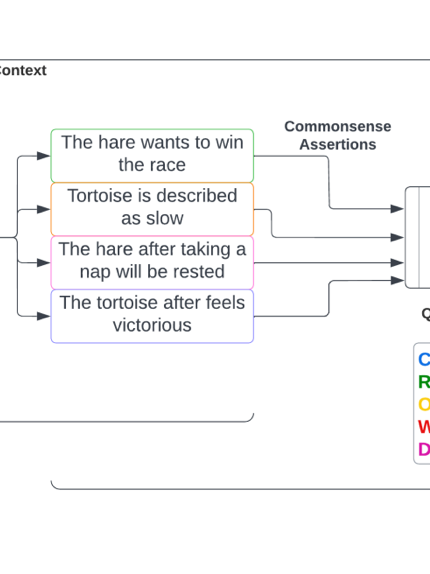
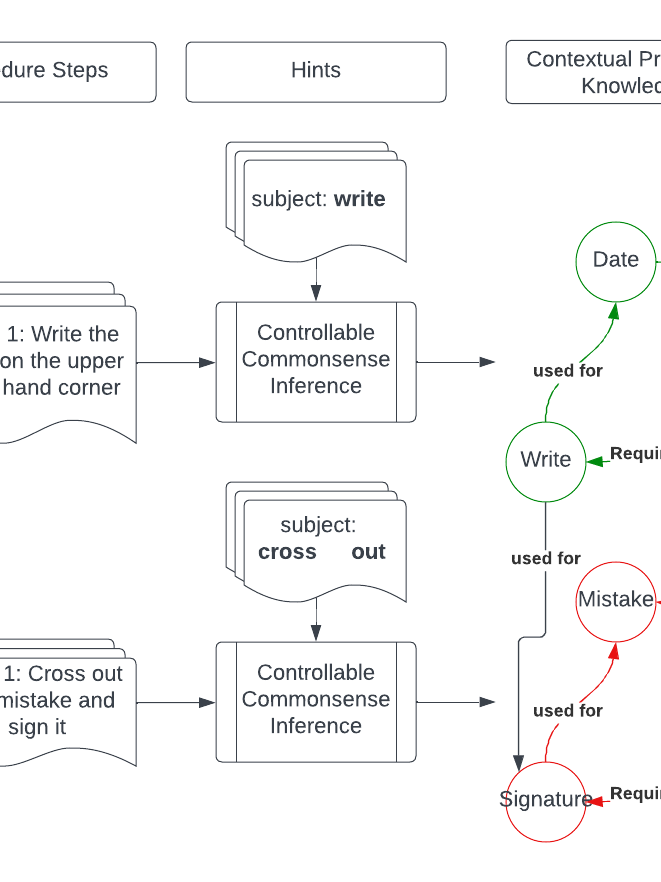
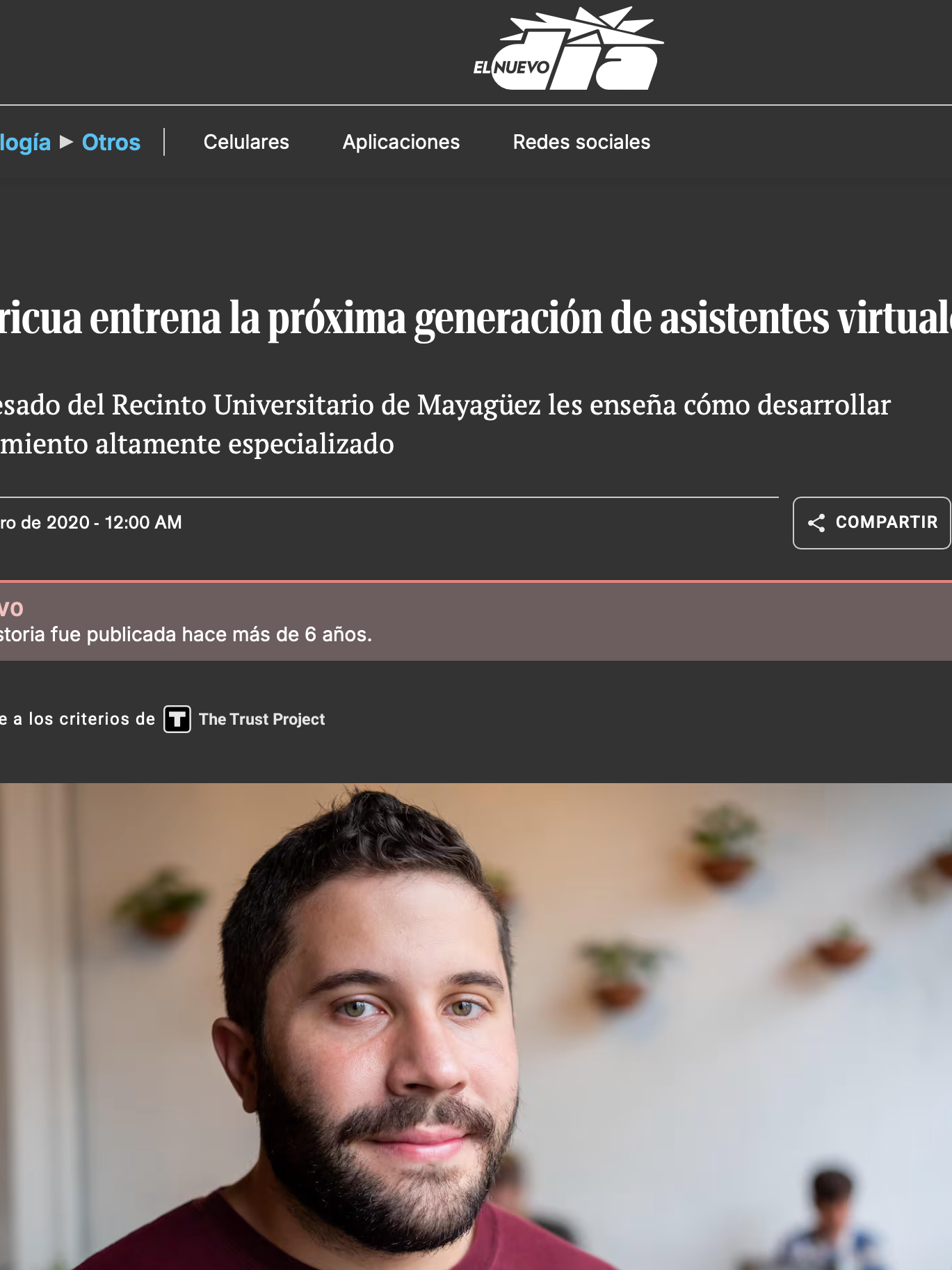
As part of the thesis work that I did, I needed some way of being able to convert a document into a knowledge graph. One of the main reasons for this is that a document's knowledge graph will be independent of the formatting structure of the document, and if we generate a commonsense graph, it may contain information that is implicit in the document. For this reason I worked to align commonsense knowledge graphs with a corpus of stories, and a sentence within that corpus. By doing this, we could then prompt a language model with the subject, relation, or object of a relation, along with the context/sentence, and have the model generate contextual commonsense relations. We called this process Hinting; we gave a hint of what to generate commonsense on, and let the model fill in the gaps. The commonsense was also designed to be both context specific, and general, without a specific context. Some of my students helped me develop synonym and antonym variations to the subjects/objects/relations to be able to make the system more robust.



Above we can see examples of the types of knowledge we utilized, the stories, and how we formatted the hints. This permitted the creation of a language model that was controllable, and could generate a knowledge graph (if we extract all nouns/verbs/noun/verb phrases, we could prompt the model to give us information from a text)